3 FieldBook (libreta de campo)
FieldBook construye libretas de campo, el cual sigue un correcta estructuración de los datos para su posterior análisis, exportando la libreta en un estructura que entienda el computador. Pero, ¿Qué son los datos estructurados?
##Datos estructurados
Nos referimos al arreglo que alberga todas las condiciones del diseño experimental, Y es el punto de partida para todo análisis que se pretenda realizar posteriormente, no prestar la debida atención a la correcta estructura de los datos no solo demandaria mayor inversión de tiempo y dinero, sino el riego inminente de echar por tierra todo el ensayo.
Motivo por el cual los datos deben de ordenarse siguiendo las siguientes consideraciones desde el comienzo:
1.- cada variable es una columna,
2.- cada obervación es una fila, y
3.- una unidad experimental por celda.
Todas estas condiciones del trabajo deben ser estructuras en una única hoja, de la siguiente manera.
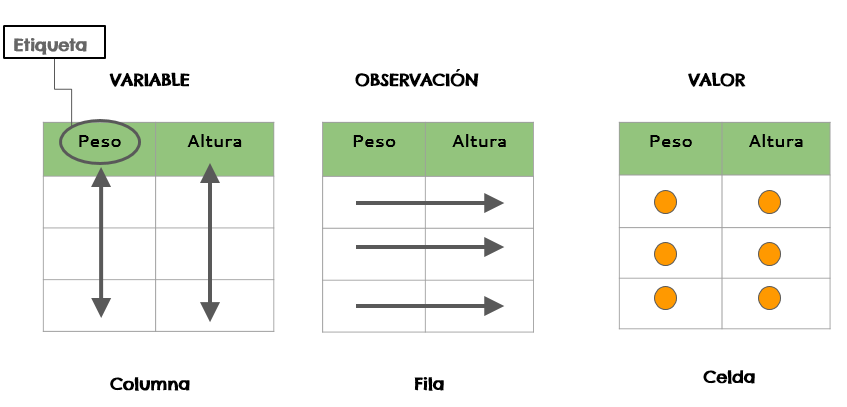
Datos Estructurados:
A continuación, un ejemplo. Se realiza un experimento donde se desea saber el efecto de una enfermedad sobre individuos de la misma especie pero diferentes cargas genéticas.
Antillano, Mexicano, Nabal, y zutano
Queremos saber como se comportan a la enfermedad “pudrición de raiz” causado por P. cinnamomi. Por tanto, para este factor tenemos dos sub-factores.
inoculado y noinoculado
Los hospederos de dicha enfermedad tendrán la condiciones del invernadero y patógeno virulante. Se deses comparar como responden estos individuos a la enfermedad. Por tal razón el diseño estadístico sera un:
Diseño completamente al azar con dos factores
De dos factores: hospedero y patógeno. Ademas, debera de evaluarse en el tiempo (8 evaluaciones) para conocer el progreso de la enfermedad, tendra 6 repeticiones en cada evaluación (6 plantas de palto) y la variable respuesta será:
Weight fresh root (kg), .........FreshRootKg
Weight dry root (Kg), ...........DryRootKg
Weight humidity root (Kg), ......Hd_rootKg
Weight fresh foliage (Kg), ......FreshFolKg
Weight dry foliage (Kg), ........DryFolKg
Weight humidity foliage (Kg), ...Hd_folKg
Length root (Km), y..............LengthRootKm
Damage root (%)..................Damage
Entoces, el libro de campo que se construya debe cumplir con el diseño que se va a ejecutar, un Diseño completamente al azar con dos factores:
factor Patogeno: inoculado y noinoculado; y el otro factor: factor Huesped: antillano, mexicano, zutano y nabal.
En la columna evaluación: se tiene a E1 (evaluacion 1); y encabezando la primera columna con la etiqueta rep contiene a las repeticiones del diseño estadístico: rep1, rep2, rep3, rep4, rep5, rep6. ( ver figura: FieldBook DCA-2factor)
Además, en las columnas “E” y “F” se ubican las variables respuestas: FreshRootKg y DryRootKg, el cual contiene los datos recogidos de cada unidad experimental. ( ver figura: FieldBook DCA-2factor)
Cada celda en la columna variable corresponde al dato recogido de una unidad experimental. En azul, el cual corresponde a la celda “E22”, se leería de la siguiente manera: La repetición 3, del tratamiento (nabal-inoculado) de la evaluación número 1, de la variable FreshRootKg, el dato recogido es: 0.0351.
De igual manera para la celda en rojo, el cual corresponde a la celda F8, se leería de la siguiente manera: La repetición 1, del tratamiento (mexicano-inoculado) de la evaluación 1, de la variable DryRootKg, el dato reogido es: 0.0168.
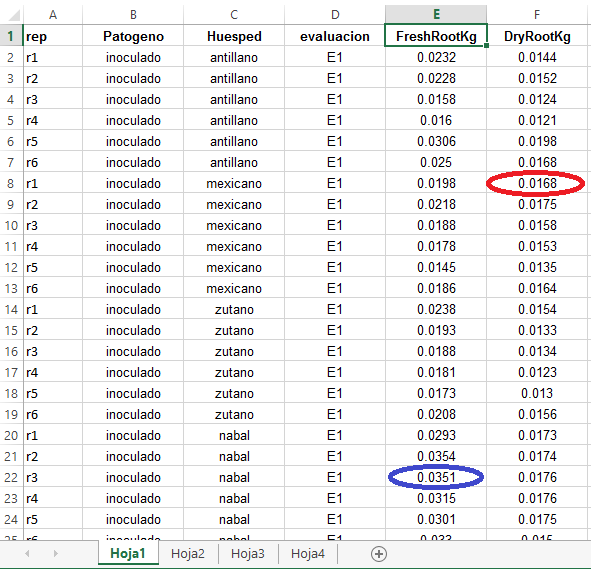
FieldBook DCA-2factor: Diseño completamente al azar con dos factores
A continuación, un ejemplo para un diseño completamente al azar, donde la evaluación en el tiempo representado por la columna intime. En este diseño los tratamientos corresponden a una sola columna denominada para esta table treatment ( T1, T2, T3, T4, T5), asi mismo las repeticiones corresponden a la columna rep (R1, R2, R3, R4) y seguidamente las variables respuestas: n_turiones, peso_turiones, n_yemas y Kg_ha.
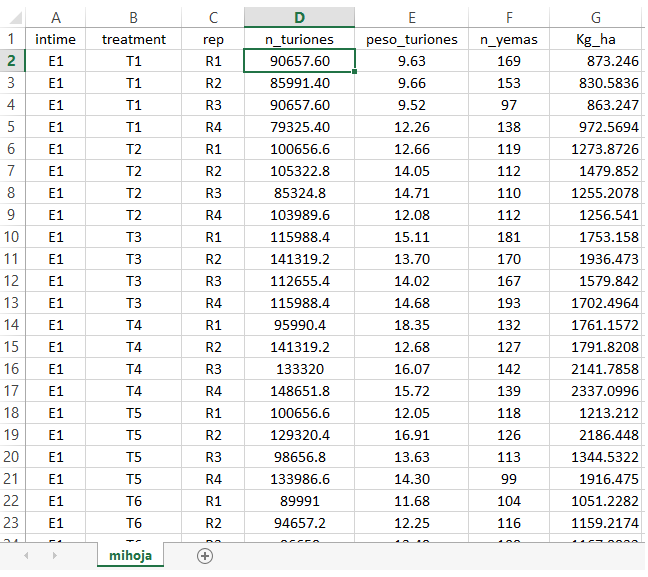
Tabla, Diseño completamente al azar
La lectura para cada celda con los datos datos serian de la misma manera, por ejemplo para D2: La repetición 1, del tratamiento T1 de la evaluacion número 1, de la variable n_turiones, el dato recogido es: 90657.60.
Es importante notar que ambas tablas alberga todas las características de los datos estructurados:
1.- cada variable es una columna,
2.- cada obervación es una fila, y
3.- una unidad experimental por celda.
##Diseño Experimental.
Fieldbook llama a la caja de dialogo Experimental Design para iniciar con la construcción y posterior exportación de la libreta de campo. En Layout elegimos el modo por defecto standard, seguidamente en la caja Design tenemos un desplegable donde se debe elegir uno de los siguientes diseños estadísticos:
Diseño completamente al Azar (DCA) / Completely randomized design (CRD)
Diseño completamente al azar (DBCA) / Randomized complete bock design (RCBD)
Diseño cuadrado latino (DCL) / Latin square design (LSD)
DCA con dos factores /Two-way factorial arrangement in completely randomized design
DBCA con dos factores / Two-way factorial arrangement in complete block design

Fieldbook: diseño de la libreta de campo
Header aquí se debe colocar el nombre del factor de variación, el cual se vizualizará en el alibreta de campo como la cabecera de la columna al que pertenece los niveles del factor (tratamientos).
Factor levels corresponde a los niveles del factor, al que corresponde el factor de variación, y van separado por comas.
Variables correponde a las variables respuestas del experimento, y tambien van separados por comas. Se recomienda como parte de las buenas practicas que esta no sea un frase o palabra larga pues asignaria por defecto una columna demasiado larga. Por ejemplo, si se desea tener tener como variable respuesta: “El peso seco de la espiga de maíz amarillo duro en miligramos”, una asignación sería: pe_AD.
recomendación: Adicionalmente se recomienda dejar anotada en una hoja adicional, la leyendas para la construcción de variables, como las unidades en las que serán medidas, la fecha, entre otras anotaciones que el responsable considere importante.
Replications Se recomienda tener un mínimo de tres repeticiones. A mayor repeticiones reducirmos el error tipo I.
Intime Corresponde a las evaluaciones que se hacen en el tiempo, por defecto figura uno, pero es normal que en un experimento se hagan muchas más evaluaciones sobre la unidad experimental.
A continuación, construiremos una libreta de campo (FieldBook) bajo un diseño en bloques completamente al azar (DBCA), con tres repeticiones, dos evaluaciones en el tiempo. para analizar tres tipos de fertilizantes (fertilizante A, fertilizante B y fertilizante C). Donde las variables respuestas serán: el peso, altura y nfrutos.
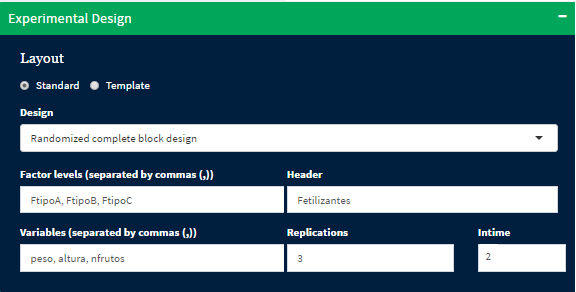
Fieldbook: diseño de la libreta de campo
Cabe precisar que para fines prácticos en este diseño las repeticiones cumplen la función de organizar los bloques, pero conceptual y teoricamente son diferentes.
En la caja de Vizualization se muestra como se contruye la libreta de campo a la medida que se ingresan los requerimientos del diseño estadístico. Para seguidamente descargarlo en el formato de su preferencia: csv ó xlsx.
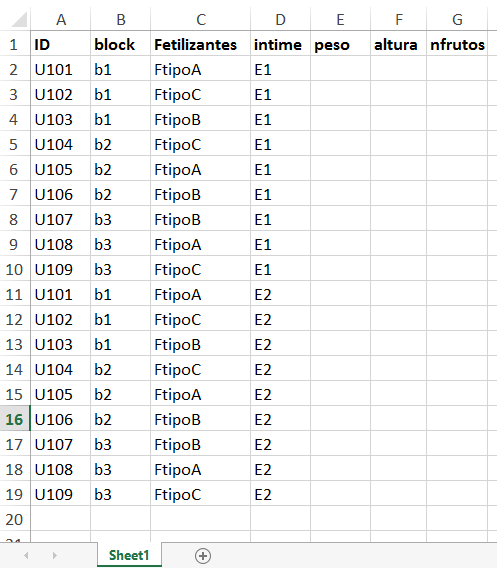
Fieldbook: diseño de la libreta de campo
Una libreta de campo constuida en FieldBook, además de exportar la libreta de campo randomizado, adiciona una columana denominada ID, el cual correspode al código de identificación de cada unidad experimenta. Por ejemplo, cuando hablamos del U102 nos referimos al tratamiento tipo de fertilizante C del bloque1. Y según el diseño va a ser evaluada dos veces, E1 y E2.
A continuación queda colectar los datos en la variable respuesta que corresponda.
3.1 Nota importante
Al ser esta una plataforma de soporte estadístico no deja de ser riguroso con la nomenclatura y símbolos raros. Evitar ingresar simbolos extraños que No pertenezcan al alfabeto ingles. Salvo en label, el programa reconoce que haces referencia a un titulo, entonces los caracteres raros solo los imprimira, mas no los analizará. Por ejemplo
palto001 incorrecto (dos tratamientos)
~~pal?to%6"“~~ incorrecto (evitar términos extraños, ???!”#$%&/()=??][{}[^)
palto_001 correcto (un tratamiento)
Palto001 correcto (un tratamiento)
evitar tildes y “ñ”
Aunque el programa soporta un mínimo de dos repeticiones, se recomienda al menos tener más de tres repeticiones. Siempre existe la posibilidad de pérdida de datos. En caso de ocurrir, mantener la plantilla tal cual y en la casilla donde corresponde el dato pérdido, dejar en blanco (nulo). No cero (0), puesto que es un valor diferente a nulo.